Una de las cosas que no he comentado por aquí es que desde hace pocos meses he estado probando el nuevo servicio Azure Load Testing, el cual podríamos considerar como la evolución del proyecto (ya deprecado) Load Testing Pipeline with JMeter, ACI and Terraform, que también estuve probando a 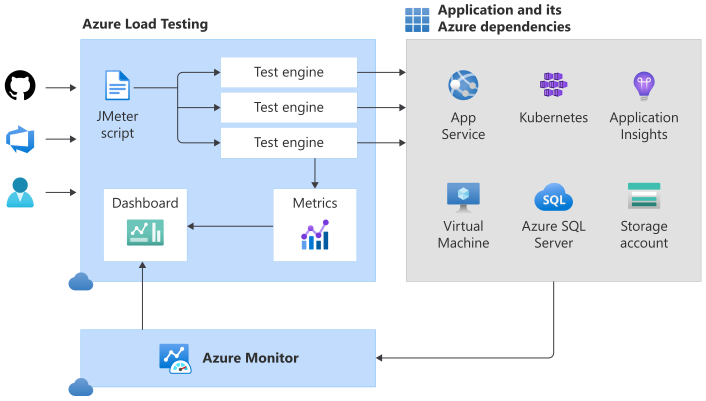 mediados del año pasado, ambas herramientas tienen como propósito la gestión automatizada de infraestructura para ejecutar pruebas de performance sobre nuestras aplicaciones, basándonos en un modelo estándar como es JMeter
mediados del año pasado, ambas herramientas tienen como propósito la gestión automatizada de infraestructura para ejecutar pruebas de performance sobre nuestras aplicaciones, basándonos en un modelo estándar como es JMeter
La verdad lo que trae el nuevo servicio es alucinante: monitoreo en paralelo de los recursos de Azure involucrados, comparación de resultados entre tests previos, integración con Azure DevOps y GitHub Actions, etc, por lo que para conocer con detalle las novedades y lo que podemos hacer con Azure Load Testing hace poco tuve la oportunidad de participar en el Meetup mensual de la comunidad DevOps Perú, así que les comparto el video, mi participación esta desde el minuto 1:21.
Aprovecho para comentar las ideas fuerzas principales alrededor de este servicio:
- A la fecha de escribir este post, el servicio aun esta en preview, pero eso no debería ser limitante para empezar a configurar nuestros planes de prueba y ejecutarlos, pues si bien no hay un SLA definido, considero (muy personalmente) que el riesgo es menor que con un servicio que si se publica de cara a nuestros usuarios.
- Debemos recordar siempre de escribir nuestros scripts .jmx considerando que van a correr dentro de un entorno Linux, lo cual implicara una ligera adaptación si nuestras pruebas actuales están configuradas para ser ejecutadas desde PCs con Windows.
- El limite de cada engine es de 250 hilos por segundo, por lo que si queremos golpear nuestra app a 1000 veces por segundo deberemos provisionar 4 engines simultáneos.
- Otro detalle a considerar es que en esta preview el numero máximo de engines que se pueden provisionar en paralelo es 45.
- Y la consideración mas critica, en este momento, es que el servicio no asigna un controlador para los engines inicializados, esto significa que si en la prueba subo un archivo .csv (para pruebas con data) de (digamos) 100 filas, y lanzo 2 engines, las filas se enviaran en su integridad a los dos engines, con lo cual tendremos 200 llamada a la aplicación a validar, si contáramos con un controlador, cada engine hubiera recibido 50 filas, pues el controlador estaría repartiendo la carga entre sus hijos. Esperemos que Microsoft mejore este detalle, pero por mientras debemos tener en cuenta la limitante que esto representa.
Bueno, espero que el video les haya sido interesante y que ya empiecen con sus pruebas! Ya saben dejen un comentario con sus opiniones que serán bien recibidas.