

Como indique en el post anterior, mi sesión «El reto del DevOps ágil» trajo buen debate e inquietudes, por lo que en el Open Space del #Agiles2014 propuse una sesión dedicada al tema de Cloud Computing, a la vez Adrian Moya propuso otra para profundizar el tema de DevOps, luego de una breve coordinación fusionamos las sesiones, así que luego del almuerzo nos reunimos en una de las salas y empezó la conversación cuyas ideas fuerzas trate de reflejar aquí:

Mas que un tema técnico, la reunión se enfoco desde el punto de vista organizacional, ver el porque las organizaciones están adoptando cloud, como lo están haciendo y también porque no lo hacen.

Dentro de las experiencias se evidencio que el cloud permite empoderar a las unidades de negocio (que usualmente tenían que esperar mucho para la asignación de un recurso *), lo cual puede lograrse mediante nube publica o mediante nube privada si es que hubiera restricciones de seguridad (generalmente por temas legales).
Algo que me llamo la atención fue que si bien un escenario PaaS (Plataform as a Service) esta mas orientado para implementar aplicaciones escalables desde el inicio, las empresas han empezado usando IaaS (Infraestructure as a Service) debido a que ya hay mas madurez en herramientas de automatización, como Puppet y Cheff, y porque este modelo no se queda tan corto como Paas aparte de que nos permite desplegar las aplicaciones ya existentes, a tenerlo en cuenta para entender las necesidades de una organización que quiera dar el salto a la nube.
Un punto clave que salto en el dialogo es que para una implementación adecuada de cloud es imprescindible medir las fortalezas de la organización, así como entender cuales son los blockers que afectarían a la organización en este proceso, en adición a los ya mencionados de seguridad y leyes hay que tener en cuenta el si la organización ya ha hecho una fuerte inversión en hardware, eso me hizo acordar lo que comento Alex Le Bienvenu de Microsoft en su momento, que ese es un escenario muy difícil de adopción y que se podría intentar entrar ofreciendo cloud como mecanismo de contingencia.
Ya metidos en el tema de los blockers afloro el tema del sector bancario, sector que (aparte del tema legal y seguridad) por su dependencia a tecnologías legacy como AS/400 y RPG se encuentran en escenarios mas complicados para poder implementar cloud, pero se menciono que algunos bancos están utilizando cloud para proyectos No Core, y que han empezado a surgir plataformas cloud especialmente orientadas a sus necesidades como FinQloud, habrá que hacer seguimiento a estas opciones.
Llegados al tema de precio, quedo claro entre los asistentes que debemos entender que el uso de cloud no necesariamente es mas barato que tener una infraestructura on premise, siendo que los ahorros van por otro lado debido a que se pueden provisionar los recursos teniendo en cuenta los picos y caída de demanda, en ese sentido es necesario validar los costes desde el principio, hacer seguimiento del consumo (un compañero comento como se les disparo la facturación mensual por una transferencia de datos) y tomar en cuenta la letra pequeña de los contratos.
El tema de desarrollo no podía ser dejado de lado y se recordo que los desarrolladores deben ser conscientes del entorno en que se va a correr la aplicación, pues de lo contrario no se podrá aprovechar las características de escalabilidad de la nube, o tener problemas al toparse con algo usualmente trivial como los FileSystem.
El tiempo paso rápido y fue un gran momento de aprendizaje mutuo para todos los asistentes, espero poder repetir esta clase de diálogos mas adelante en Perú o en próximos Ágiles.
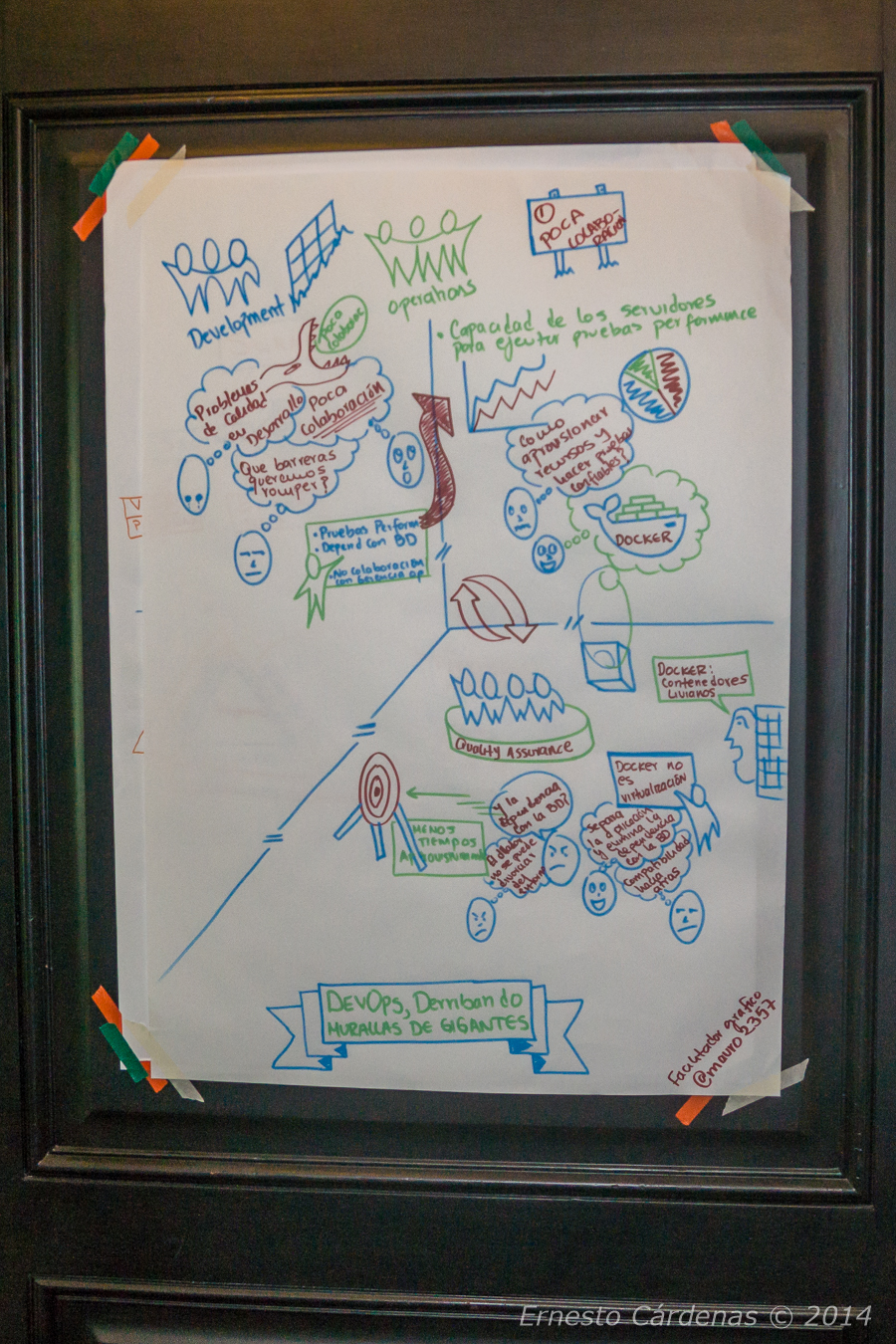
Luego los amigos de Tech & Solve tuvieron otra charla donde comentaron su experiencia y problemas en la evolución del modelo DevOps, donde de paso nos explicaron sobre un producto muy interesante: Docker que están utilizando como una manera ágil para poder provisionar infraestructura (de momento Linux) vía código de manera sencilla, como feedback ante sus problemas debemos recordar que la tendencia DevOps se trata de colaboración entre áreas para llegar a soluciones y no centrarse unicamente en lo técnico, esto viene después.
Ademas de Adrian, un gran agradecimiento a Diego Garber (extremo derecho en la foto **) que estuvo presente en todas estas sesiones compartiendo su experiencia y punto de vista.

* Como dije en otro post, en este blog no usamos la palabra «recursos» para referirnos a las personas, siendo que en este caso usamos la palabra para referirnos a maquinas físicas, maquinas virtuales, espacio en disco, websites…
** El asistente del medio también estuvo muy presente y activo en estas sesiones DevOps, pero se me paso apuntar su nombre, así que si alguno de los asistentes al Ágiles lo puede identificar se agradecerá.





 En todo caso una duda que tenía desde que se anunciaron las primeras versiones de prueba de Windows 8 era sobre el destino del Windows XP Mode (en simple: una máquina Virtual de XP muy integrada con Windows 7), siendo que el soporte de Windows XP acaba el 2014 y que W8 retira a MS Virtual PC para adoptar la tecnología Hyper-V (existente desde Windows 2008 Server) Microsoft decidió descontinuar Windows XP Mode ofreciendo como única alternativa el
En todo caso una duda que tenía desde que se anunciaron las primeras versiones de prueba de Windows 8 era sobre el destino del Windows XP Mode (en simple: una máquina Virtual de XP muy integrada con Windows 7), siendo que el soporte de Windows XP acaba el 2014 y que W8 retira a MS Virtual PC para adoptar la tecnología Hyper-V (existente desde Windows 2008 Server) Microsoft decidió descontinuar Windows XP Mode ofreciendo como única alternativa el 



