

Aquí de vuelta al ruedo con el nuevo año, en este tiempo de ausencia desde el Microsoft Ignite, le he prestado atención a un tema muy apasionante cuyo uso e interes ha ido creciendo en los últimos años: computación serverless, así que visto el estado actual repasaremos donde estamos y hacia donde podemos ir mediante el uso de esta tecnología, especialmente con las mejoras introducidas en Azure.
A estas alturas se han dado muchas definiciones sobre lo que implican los componentes serverless, pero es mejor basarnos en lo que debería componer usualmente una arquitectura/componente serverless:
- Abstracción sobre los servidores utilizados. Que si, al final todo proceso computacional requiere tener hardware (servidores) por detrás, pero la diferencia es que tanto nos abstraemos sobre ellos, no que no existan; nuestras queridas amigas las Web Apps ofrecen un buen nivel de abstracción (ya no tenemos que tunear el Sistema Operativo, por ejemplo), pero con serverless damos un paso mas allá, esencialmente lo que nos importa es tener donde ejecutar nuestras porciones de código.
- Basado en eventos. Este tal vez sea uno de los componentes mas difícil de entender, pues para lograr efectos similares, a lo que estábamos acostumbrados es a tener procesos que cada x porción de tiempo validaban si una condición se había efectuado o no, para con ello invocar la ejecución de una acción o programa. Con este modelo basicamente vinculamos una acción sobre un recurso (una escritura de archivos, una petición HTTP, la escritura sobre una cola, un timer, etc) con un programa, y listo, sera la propia infraestructura cloud la que se haga cargo de invocar nuestro programa cuando la condición se cumpla.
- Escalamiento inmediato. Esto es mas sencillo de entender, si tienes muchas peticiones o uso de computo sobre tu aplicación serverless, el sistema debe ser capaz de agregar las instancias necesarias para cumplir la demanda requerida, y claro reducirla cuando el pico termine.
- Pago por uso. Bueno, eso es lo que se tiene mas claro cuando se trata de nube, en este caso significa solo pagar cuando nuestros programas sean invocados, aunque esto tiene algunos matices como veremos luego.
Eso es la teoría, pero la practica ha implicado algunas consideraciones adicionales, como por ejemplo en el caso de que nuestros programas requieran operar bajo demanda no continua, eso quiere decir que si pasado un tiempo determinado, el recurso de computo que estemos usando deja de ser utilizado/invocado, este se apagara y cuando requiramos su uso, tendremos que crear una instancia nueva para efectuar el trabajo solicitado, esto lo hace el sistema tras bastidores y no tenemos rol en lo que ocurre, peroooo igual toma un tiempo de aprovisionamiento que puede retrasar la ejecución real de nuestros eventos, a este fenómeno se le llama «cold start» y ha sido gestionado por los proveedores de nube y sus usuarios de distinta manera.
La primera forma empleada por los usuarios era que periódicamente se disparara un evento que invocara la ejecución de un método, de esta manera la instancia nunca se apagaría, por otro lado los fabricantes ofrecieron la opción de tener siempre un recurso encendido y dedicado, de esta manera no habria cold start, si, esto implica una cierta «sacada de vuelta» al concepto de serverless «puro», pero a veces la realidad obliga a tomar este tipo de decisiones (*).
Con esto en mente el escenario puede perfilarse un poco mas, para casos en los que a pesar de tener momentos idle se requiere respuesta inmediata, sera conveniente escoger modelos como el de Azure Functions Premium, pero si no nos es problema el esperar un poco para atender un proceso de poca demanda, elegir un modo que privilegie el pagar exclusivamente por uso sería lo mejor para la economía de nuestros proyectos.
Ok, ya tenemos claro esto de los modos de consumo y facturación, pero… ¿cómo ha evolucionado su uso y que cambios están por alterar la forma en que se desarrollan las aplicaciones serverless? Bueno, cabe indicar que a estas alturas la propia practica ha terminado de consolidar dos escenarios principales para su uso:
- Una forma sencilla de definir APIs REST
- Un modelo programático basado en eventos alrededor de recursos en la nube
Y claro, cada uno de estos escenarios tiene sus propias reglas y forma de abordar los problemas, pero… hay necesidades que han aflorado ¿serverless me permite gestionar procesos complejos? ¿es posible interactuar con recursos en redes privadas o alojados on premise? y la verdad es que la respuesta no es sencilla, pero todo tiene solución.
Sobre los procesos complejos, cabe indicar que cuando se empezó con las implementaciones serverless, la idea 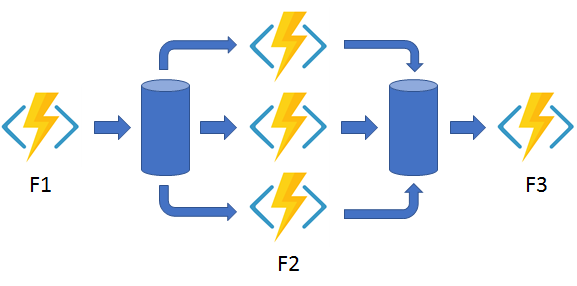 primigenia era hacer procesos cortos, que devolvieran rápidamente el control al proceso que los disparara, vamos no para bucles largos de varios minutos; pero claro, basta que surja una nueva tecnología para que se le expriman los limites y así, las necesidades planteadas en este aspecto son:
primigenia era hacer procesos cortos, que devolvieran rápidamente el control al proceso que los disparara, vamos no para bucles largos de varios minutos; pero claro, basta que surja una nueva tecnología para que se le expriman los limites y así, las necesidades planteadas en este aspecto son:
- ¿Qué hacer si necesito ejecutar un proceso largo? De partida, la limitación viene dada por los timeout que te define tu entorno de ejecución, eso ha sido mejorado mediante Azure Functions Premium (en el caso de AWS se han agregado mas opciones a sus Lambda para lograr el resultado) que permite definir tiempos de timeout mas largos que los proveídos por los modo Consumption y App Service, pero claro.. hay que obrar con prudencia y validando bien los escenarios.
- ¿Como usar librerías no proveídas por mi entorno serverless? Ahh, porque eso no lo conté, cuando uno usa Azure Functions, uno tiene acceso a un conjunto bien razonable de librerías para incluir en el programa, especialmente las proveídas por .Net Core, pero y ¿si uno necesita usar ESA librería de terceros? la solución es sencilla, despliega tu Function como contenedor, pues la plataforma soporta ese mecanismo, y de esta manera la imagen saldrá empaquetada con todas las dependencias requeridas.
- Ok, pero ¿si mi aplicación es realmente compleja? ¿Con invocaciones a distintos procesos que deben ser orquestados? Bueno, en ese caso la solución técnica viene dada por las Durable Functions (**), una extensión a Azure Functions que permite orquestar Funciones en secuencia, en paralelo, asíncronas, etc, pero claro este poder lleva la responsabilidad de definir bien la arquitectura de los procesos a ser gestionados, así que un poco de calma a la hora de acometer estos escenarios.
Y bueno, es todo por ahora, que si no se hace muy largo, la próxima semana comentare lo que esta cambiando respecto a las interacciones de Azure Functions con redes privadas y on premise. De paso aprovecharemos para reflexionar sobre las ventajas de Serverless sobre otros modelos de escalamiento y las opciones que hay para aplicar el concepto en On Premise. Espero tus comentarios.
(*) A pesar de que Cornelia Davis no este muy de acuerdo con esto.
(**) En el caso de AWS serian las Step Functions.
5 thoughts on “Serverless: Realidad y perspectivas (1)”